Нейросеть научили менять ракурс съемки обычного видео
Американские исследователи разработали алгоритм, позволяющий смотреть уже записанное видео с другого ракурса. Новому алгоритму, в отличие от почти всех предыдущих, для этой задачи достаточно для съемки одной камеры, а не массива. Статья опубликована на arXiv.org.
Мы воспринимаем мир благодаря стереоскопическому зрению, которое в свою очередь возникает из-за того, что у нас есть два глаза. Благодаря этому мозг получает два изображения, которые, хотя и похожи друг на друга, немного различаются, потому что «сняты» с немного разных ракурсов.

Инженеры уже несколько десятилетий работают над созданием устройств для просмотра объемных изображений и видеороликов, и эти разработки можно разделить на две основные части: аппаратные и программные. Первые — это устройства, непосредственно отвечающие за просмотр объемного контента. Среди них можно выделить экраны светового поля и VR-очки. Программные разработки в основном сосредоточены на создании и хранении объемных данных. К примеру, в прошлом году разработчики из Google создали массив камер и научились совмещать кадры с него так, чтобы затем снятое видео можно было просматривать с разных ракурсов.
Но на текущий момент практически все видеоролики сняты на одну камеру, поэтому их нельзя преобразовать в объемные таким способом. Разработчики из Политехнического университета Виргинии и Facebook под руководством Цзя-Биня Хуана (Jia-Bin Huang) создали алгоритм, получающий обычное 2D-видео и синтезирующий для него кадры с произвольных новых ракурсов.
Новый алгоритм основан на нейросети NeRF (Neural Radiance Field), разработанной другими исследователями в 2020 году. Она позволяет хранить информацию о 3D-сцене и рендерить ее 2D-изображения с произвольного угла. Алгоритм рендерит изображения попиксельно, посылая лучи через сцену: она получает от пользователя точку и направление наблюдения. Пропустив луч, нейросеть выдает полученные вдоль него значения плотности и цвета, на основе которых задается цвет пикселя 2D-изображения. Затем процесс повторяется для множества направлений, в результате чего образуется полный кадр.
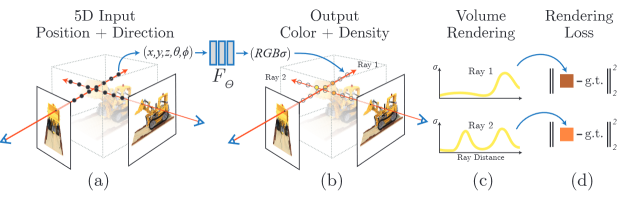
Схема создания 2D-изображения из 3D-представления алгоритмом NeRF
NeRF-модели обучаются на множестве кадров одного и того же объекта, снятых с разных ракурсов. В случае с видеороликом задача усложняется, потому что для каждого момента времени есть только один кадр с одного ракурса. В новой работе авторы предложили параллельно обучать две отдельные модели: для подвижных и неподвижных частей сцены. Статическая модель аналогична обычной NeRF-модели, за исключением того, что при ее обучении из кадров удаляли фрагменты с подвижными объектами.
Для обучения динамической модели и решения проблемы нехватки кадров исследователи предложили создавать для каждого кадра и соответствующего момента времени t по два дополнительных кадра, «снятых» в моменты t+1 и t-1. Для этого алгоритм предсказывает 3D-поток между соседними моментами времени, который по своей сути аналогичен понятию оптического потока с той разницей, что он отражает движения для 3D-данных, тогда как оптический поток отражает движение между 2D-кадрами.
Это, а также функции потерь, повышающие качество обучения динамической модели, позволило научить алгоритм качественно воссоздавать кадры с новых ракурсов для видео с подвижными объектами. Кроме того, он позволяет отделить движение основной части сцены от движения динамических объектов. К примеру, в демонстрационном ролике можно увидеть, как алгоритм позволил превратить видео, на котором оператор шел параллельно с танцующим мужчиной, в статичное, «снятое» с одного места. Авторы сравнили работу своего алгоритма с аналогом, созданным другой группой исследователей в 2020 году, и устроенным иным образом, и показали, что новая разработка дает более плавные переходы между ракурсами и меньше артефактов геометрии, но при этом делает кадры чуть более размытыми.
Источник: nplus1.ru






{kind=link}
{kind=link}